- 0. 要旨
- 1. きっかけ:セルフBIによるデータの民主化の先を考えた
- 2. 過去からの振り返り:BI以前
- 3. 次の世代のイメージ:第4世代
- 4. データとの向き合い方
- 5. 結果のアウトプット
- 6. まとめ:より主体性を高くする
0. 要旨
- BIによるデータの分析は、コードによるデータの定義が重要になる
- ついでにクラウドといった環境により、アウトプットがスケール可能になる
1. きっかけ:セルフBIによるデータの民主化の先を考えた
この前、知人とTableauやPowerBIといったBIツールの話をしたのが最初。 そこでふと今のBIってどうなんだろうと考えました。
BIツールでの分析
BIツールを使うと、データを取り込んで自分で分析することができます。 例えば、社員ごとの売り上げの一覧のデータがあれば、一覧をそのまま見ることも、合計や平均を計算したり集計ができます。 ツールの操作が、マウスや簡単なキーボード操作で出来るのも、メリットです。
セルフBIでデータの民主化
業務でより高度な分析が必要になると、データを組み合わせが必要になります。 例えば、社員ごとの売上の内訳、どの商品が売れたのか。またその商品の原価はそれぞれいくらか。 社員が営業のそれぞれどの組織に所属しているか。組織ごとに特徴があるか。 組み合わせるデータがまるでレゴのブロックのように、パーツが増えるとできることが増えます。 そうやって組み合わせを、分析したい人自身が行うことがセルフBIです。 組み合わせができるデータがあれば、誰もがデータができます。
組み合わせのプロを目指す?
そんなセルフBIですが、問題も抱えています。 問題が起きるのは、業務の規模が大きくなる時。 業務ごとにデータの種類が増えたり、時間とともにデータの量が増えたり。 そのためには、どう組み合わせるのが良いのか、高いレベルが求められます。 いわば、BIツールを使う人みんなが、データを組み合わせるプロである。 そんなプロを目指していくのはとても大変です。
セルフゆえに他の人まで配慮が難しい
また、個人がレポートを一人で作りこむことの問題もあります。 BIツールの中でどのような組み合わせをしたのか、作った人の暗黙知になりがちです。 もちろん作ったレポートの中身を見て確認もできますが、その作業も大変です。 セルフBIができるデータの民主化は、その人自身で終わりがちです。
データの組み合わせはデータ基盤で
そのため、データの組み合わせをレポートを作るユーザではなく、データを提供する基盤で行う。 そのような流れがあります。 個人で管理をするより、共通の管理をした方がいいのは間違いないですね。
セルフBIの先で必要なもの
昔は確かにシステム側でデータを取りまとめて、ユーザは貰ったデータでレポートを作る。 だからユーザのデータ分析のできる範囲が限られていました。 では、そこに戻るだけなのか、たぶんそうではないはずです。 セルフBIの先でユーザは何をするのか、考える必要があるのでは。 そんな話がきっかけでした。
2. 過去からの振り返り:BI以前
セルフBIの先で必要なものは何か。 ユーザの視点で考えていきました。
データ活用は業務の課題を解決するため
ユーザにとってデータ活用の目的は何か。 簡単にいうと、業務の課題を解決するためです。 業務の課題をどう解決するか、分析とは何か。 それを考えていくとよさそうです。
データ活用をBI以前からふりかえる
分析をするためにBIツールを使うとしたら、今まではどうだったのか。 BIツールが生まれる以前から仕事の中でデータを活用しているはず。 そう思って、BI以前のデータ活用を振り返ってみました。
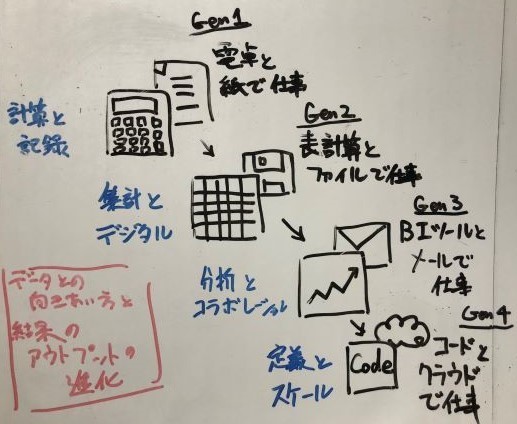
第1世代 電卓と紙で仕事をする
まだPCも無かった時代。 紙の書類で手書きをするか、ワープロで印刷した紙を使っていた時。 そろばんを使う人もいたかと思いますが、電卓を使っているイメージ。 職場がWindows95のPCが発売されるまでは本当にそんな環境でした。 ただ、そんな中でも紙には項目を一覧で書くこともできました。 電卓で四則演算を駆使して、合計や平均も出してデータを使っていました。
第2世代 表計算とファイルで仕事をする
それからPCが職場に普及してくると、MicrosoftのExcelのような表計算ソフトが使われます。 縦と横に項目があり、数値の組み合わせがとても柔軟になってきます。 そしてPCを使う最大のメリットとして、ファイルで保存をして再利用もできるようになります。 業務事態もPCを使うようになると、業務システムが導入されます。 データの分析は業務システムからデータをファイルでもらうこともできるように。 もらったファイルはExcelに取り込んで使うことができます。
第3世代 BIツールとメールで仕事をする
ファイルでデータをもらうっていたものが、データ活用をするための分析システムに変わります。 分析のデータをとりまとめるためのシステムが整備されていきました。 Excelを使っていたユーザは、直接分析システムのデータを使うことが便利になりました。 そのツールこそがBIツールになります。 またデータのファイルも、メールや様々なメッセージアプリでのやり取りができるように。
3. 次の世代のイメージ:第4世代
ここまでBI以前を振り返ってどんな仕事の環境だったのか。 イメージしていくと、なんとなく整理できた気がします。 では、次の世代のイメージはどうなのか。 今キャッチアップした最近のトレンドから探ってみます。
Looker、Databricks、dbt:データをメタで取り扱う
LookerはセルフBIの次の形だと言われています。 具体的にはデータマートを抽象化して管理しやすくしたものです。 DatabricksはデータレイクとDWHのいいとこどり。 データのストレージを抽象化したデータレイクと、DBの構造をクエリエンジンで扱いやすくしたもの。 dbtはSQLでのデータ管理を抽象的かつ構造的にしたもの。 それぞれはツールやプラットフォームですが、データを抽象的、メタとして扱いたい感じです。
VSCode、Windowsターミナル、Winget:テキストによる操作
VscodeはテキストエディタをベースにしたIDE環境。 プログラミング言語での開発に役立つ機能拡張やGit、Markdown、CSV、ターミナルさえも使えます。 コマンドパレットと呼ばれるコマンドを呼び出しての操作も可能。 Windosターミナルは、コマンドプロンプトやPowerShellだけでなく、WSLなどのLinuxも使えるます。 このタイミングでテキストで処理をさせるためのターミナルソフトをMicrosoft純正で提供。 wingetも純正のコマンドベースのインストーラーです。 これらの一式はWindowsがGUIでの操作だけではなく、テキストによる操作を一方で推奨しているのです。
データガバナンス、データマネジメント:データを主体的に管理する
データをどう取り扱うのがよいか。 DMBOKでも記載がありますが、それがデータガバナンスとデータマネジメントです。 これらはデータを使うユーザこそデータがちゃんとしていないことの影響を受けると説いています。 そのため、データを主体的にユーザが管理することが重要です。
第4世代:コードとクラウドで仕事をする
それらを踏まえると、まずテキストベースでのデータの取り扱いが考えられます。 例えばSQLのようにコードを書いて、コードベースでデータを取り扱うこと。 PythonやRのようにプロットやグラフもコードで表現するのもイメージできそうですね。 また、紙からファイル、メールといった流れから、クラウドでの仕事と言ってよさそうです。 クラウドを使うというのは、URLをシェアしたり、APIで連携したりといったイメージになります。
4. データとの向き合い方
ここまで世代を振り返り、次世代をイメージしてきました。 その世代ごとに何が変化したのか、データとの向き合い方が進化したのでは。 そういった視点で考えていきます。
データ活用のイメージ
データとの向き合い方を考えるうえで、参考までにデータのイメージがあるといいかもしれません。 例えば、ある事業の課題の解決のデータ活用です。 その業務の「目標を定めて」「所定の期間で」「現状から実績を積み上げます」。 目標値、期間、実績値。 他にも、費用や担当者といったデータがありそうですね。
第1世代 計算
電卓を使うことで、計算を駆使することができるようになりました。 平均、割合、比率。 どれぐらいのペースで実績を出しているのか。 費用が効果的か。 統計的な考え方ができるようになったといってもいいでしょう。
第2世代 集計
表計算を使うことで、データは値からリストに、リストから表になっていきます。 すると、クロス集計やピポットといった表計算でお馴染みの比較ができます。 グループ分け、フィルター抽出、結合などもあります。
第3世代 分析
BIツールを使うことで、グラフや図によるデータの可視化。 操作がさらに直感的にできるようになったインタラクティブ性。 さらにデータの自動更新が可能になり、レポーティングとしての機能も重視されます。 大局的に特徴を捉えること、試行錯誤を伴うPDCAを回していくことが可能になっていきます。
第4世代 定義
では、コードを使うことがデータ活用になった場合。 コードで実現できることは、型、条件、範囲、命名、分岐といった定義になります。 定義を行うことでデータ活用に必要な要素を定める。 それが一番重要になります。 要素が定まれば、あとはその範囲の中で変化する値としてパラメータを調整します。
5. 結果のアウトプット
データの向き合い方が進化からセルフBIの次を考えました。 もう一つの視点として、データ活用をその結果をどのようにアウトプットするのか。 アウトプットの進化から考えていきます。
第1世代 記録
紙の一番の役割は記録ができることです。 計算した結果、収集したデータ。 それをすべて紙に記録することで結果を別のところにアウトプットすることができます。 まず結果を残そうというのは今でももちろん重要です。
第2世代 デジタル
PCでファイルを取り扱えるというのは、デジタルであるということです。 デジタルとしての特徴。同一性が担保していること、再利用ができることです。 アウトプットとして、データの品質にかかわる重要なところです。
第3世代 コラボレーション
メールやメッセージアプリの役割は、アウトプットの相手とやり取りがしやすくなったということです。 アウトプットを別の利用者に展開できることで、価値がさらに高まっていきます。
第4世代 スケール
クラウドでのアウトプットとは、同時に複数の利用者と利用できること。 人だけではなく、APIがつながるあらゆるシステムとその先の利用者をつなぎます。 アウトプットの利用の広がりを最大化していく、そのような進化になっていくでしょう。
6. まとめ:より主体性を高くする
BIによるデータの分析は、次の世代ではコードによるデータの定義が重要になると予想します。 それは業務のこれまでの変化と、さらにデータの取り扱い方の進化を踏まえたものです。 ついでにクラウドといった環境により、アウトプットが進化し、よりスケールしていきます。 それは、セルフBIの先により主体性を持ってデータ活用をする利用者であるということにつきます。